目次
- Windows 編
- macOS 編
WhisperX で音声認識と話者分離をしてみよう
Windows 編
FFmpeg のインストール
WhisperX を用いて音声認識や話者分離を行うためには,FFmpeg が必要です.FFmpeg ダウンロードサイト (https://www.gyan.dev/ffmpeg/builds/#release-builds) から ffmpeg-release-essentials.zip をダウンロードし,任意の場所に展開します.
今回は C:\ffmpeg\ に設置しました.ここで,C:\ffmpeg\bin\ というフォルダが存在していることを確認してください.
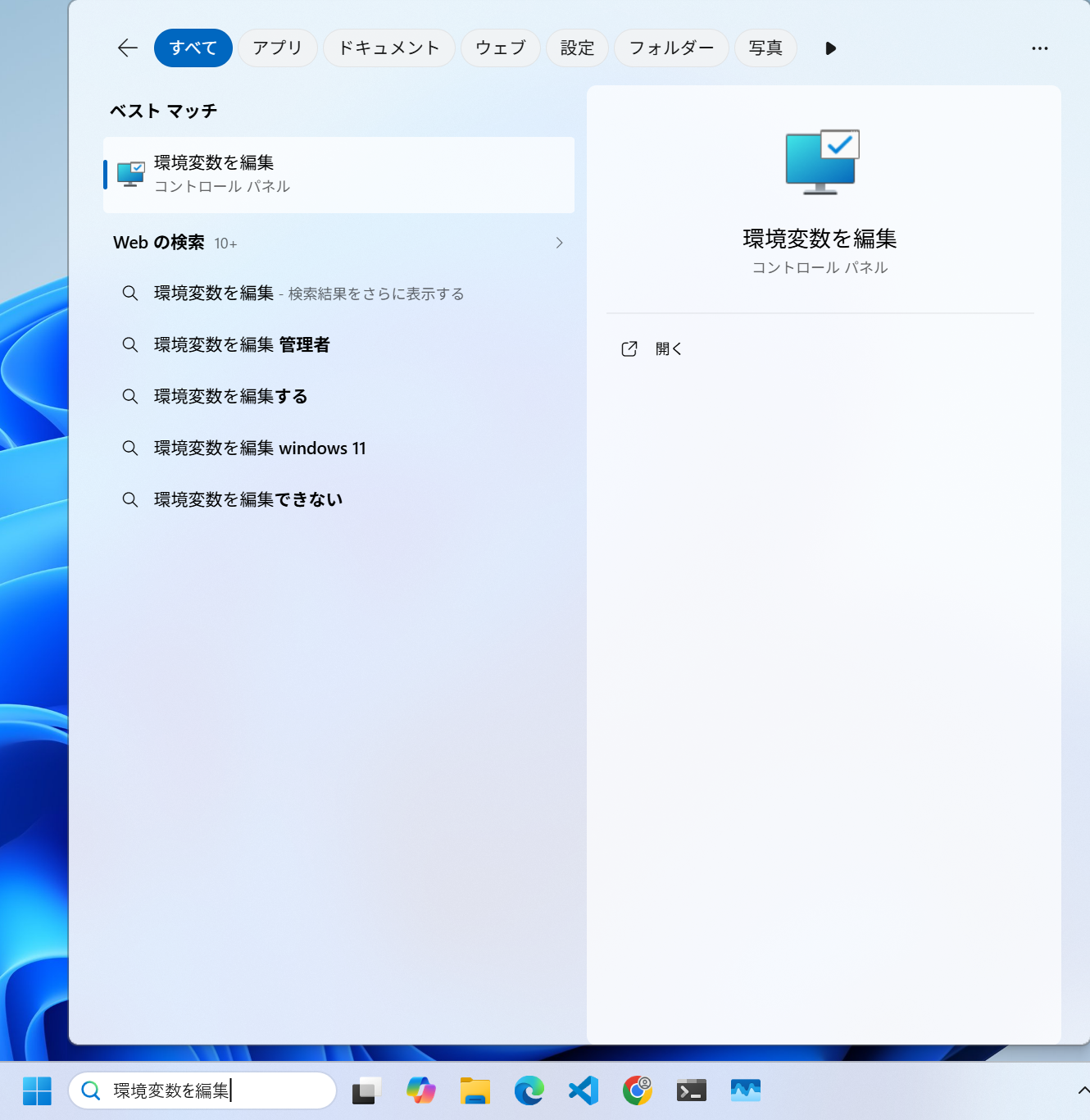
次に,Python から ffmpeg が利用できるように環境変数 (path) の設定を行います.次の図の通り,Windows の検索ボックスに「環境変数を編集」と入力し,検索結果に表示されたアプリ(コントロールパネル)を起動します.
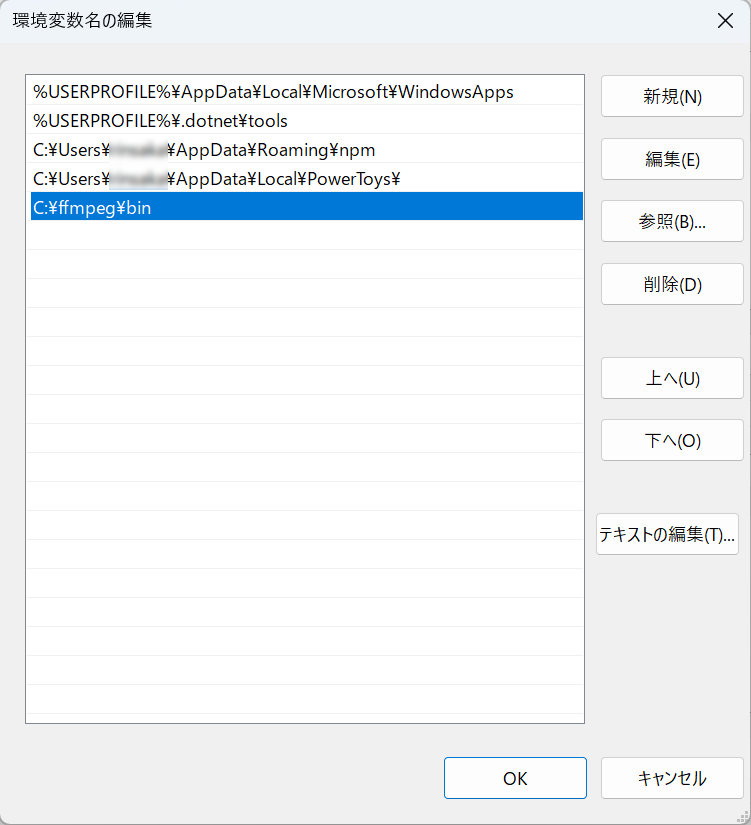
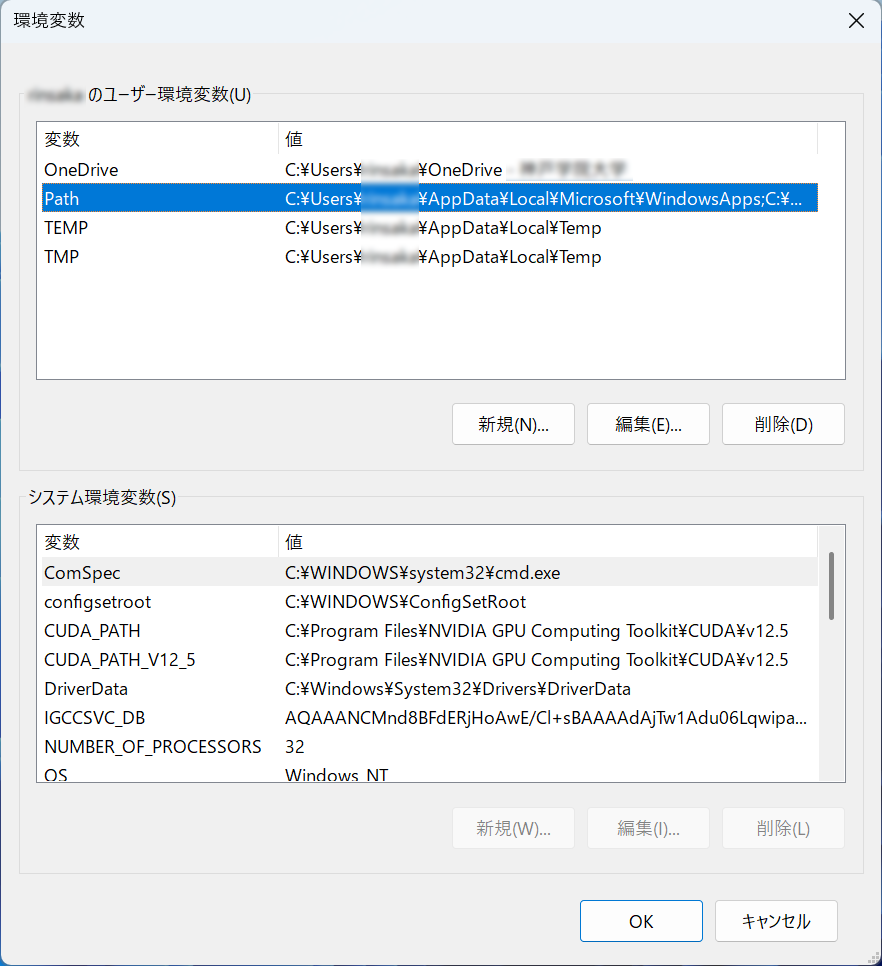
次に「ユーザー環境変数」の「Path」を選択し,「編集」ボタンをクリックします.
次の画面のとおり,「C:\ffmpeg\bin」を追加し「OK」をクリックします.これで FFmpeg が利用できるようになりました.