巡回セールスマン問題を解いてみよう
目次
はじめに
複数の地点(都市やセールス拠点など)があり,すべての地点をちょうど一度ずつ訪問して出発地点に戻ることを考えます.このとき,総移動コスト(移動距離や移動時間)が最小になるような巡回経路を求める問題を巡回セールスマン問題 (Traveling Salesman Problem: TSP) と呼びます.この問題は組み合わせ最適化問題として考えることができます.
例えば,地点 1 を始点とし,地点 2, 3, 4, 5 をちょうど一度ずつ訪問して地点 1 に戻る場合を考えます.地点1から最初に訪問する地点の候補は 2, 3, 4, 5 の 4ヶ所あり,その次に訪問する候補は 3ヶ所,・・・となります.つまり,\(n\) 地点の巡回セールスマン問題においてすべての巡回経路の候補を列挙すると \((n-1)!\) 種類となります.\(n = 5\) のとき \(4! = 1 \times 2 \times 3 \times 4 = 24\) 通りですが,\(n = 10\) のときおよそ36万種類,\(n = 20\) のとき 2.4E+18 種類となり,\(n\) の増加に対して経路の種類は急速に増加してしまいます.
巡回セールスマン問題を解く
はじめに必要なパッケージをインポートします.データフレームを利用するための pandas,グラフを描画するための matplotlib,地点間の距離を求めるための scipy,そして巡回セールスマン問題を解くための ortoolpy です.ここで,ortoolpy のインストール方法についてはこちらを参照してください.また,後の作業で近似解法を利用する場合は同じような方法で ortools もインストールしてください.
パッケージのインポート
import pandas as pd
import matplotlib.pyplot as plt
from scipy.spatial import distance
from ortoolpy import tsp
次にノード(地点)データを準備します.例えば,\(x\), \(y\) 座標が与えられた9個の地点データを二次元リストとして準備します.
ノード(地点)データを準備
nodes = [
[2000,1000],
[5000,2000],
[6000,7000],
[8000,2000],
[1000,6000],
[7000,3000],
[3000,4000],
[5000,5000],
[4000,7000],
]
このノードデータをPandasのデータフレームに変換します.
データフレームに変換
df = pd.DataFrame(nodes, columns=["x", "y"])
print(df)
x y 0 2000 1000 1 5000 2000 2 6000 7000 3 8000 2000 4 1000 6000 5 7000 3000 6 3000 4000 7 5000 5000 8 4000 7000
イメージをつかむために,ノードの位置をグラフにプロットします.このとき,あとで最短路を線でつないで描くことから散布図ではなく折れ線グラフを利用し,marker='o' によって座標点を円でプロットし,linestyle=''によって線なしにします.
ノードをプロット
fig, ax = plt.subplots(1, 1, figsize=(6, 6))
ax.plot(df.x, df.y, linestyle='', marker='o')
ax.set_xlabel('x')
ax.set_ylabel('y')
plt.show()
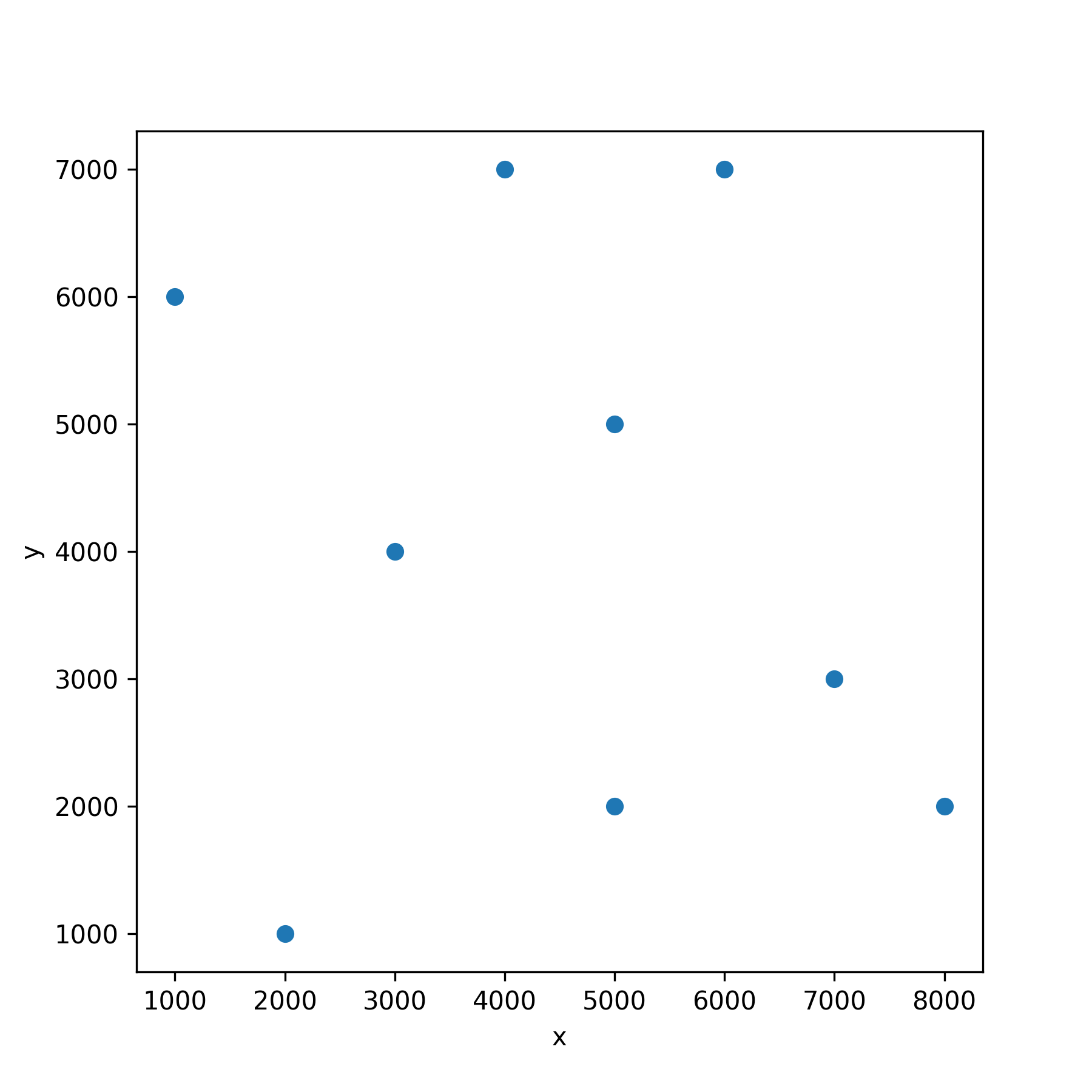
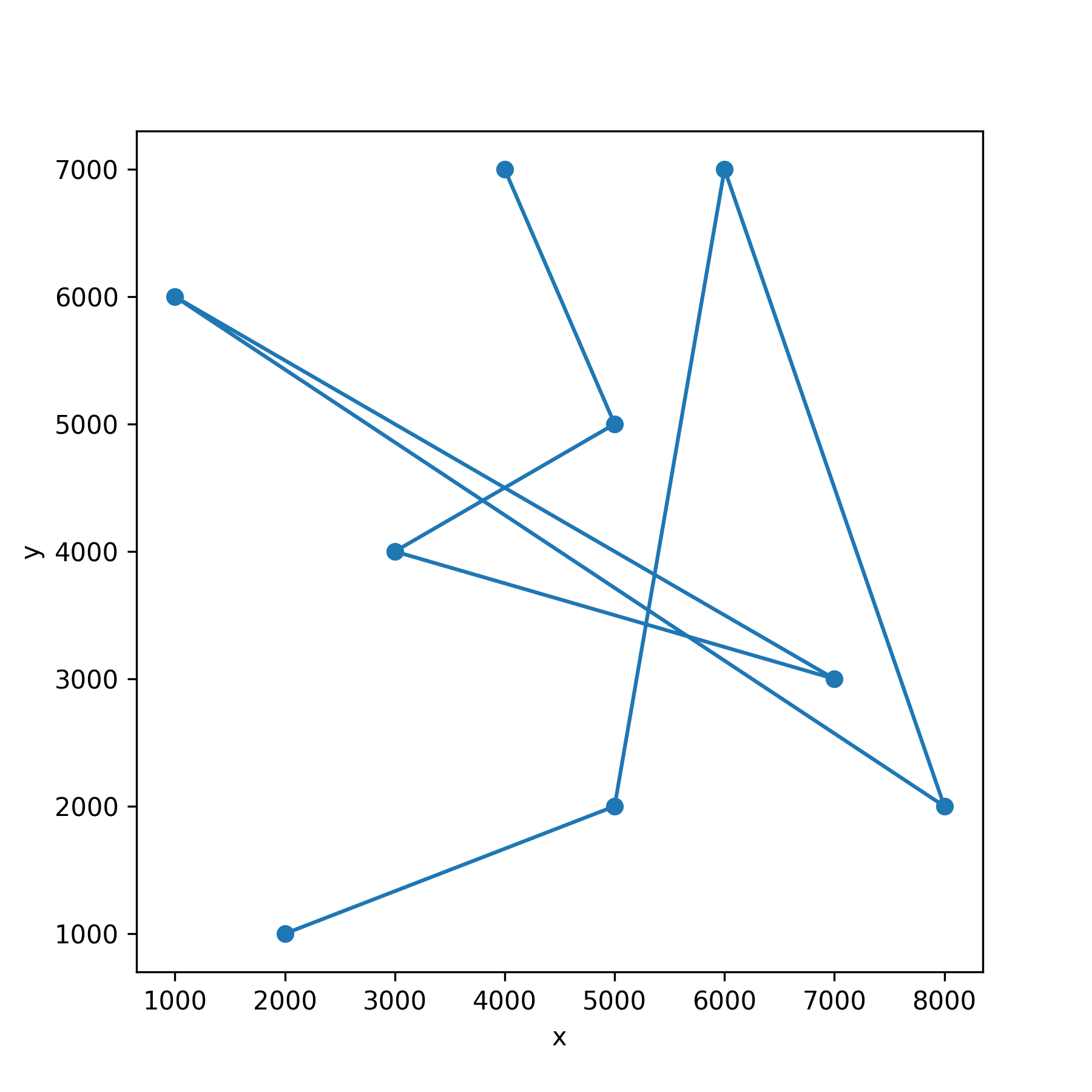
試しにノードの定義順に経路をつないでみます.しかしながら,明らかにこの経路は最短の巡回経路ではなさそうです.
fig, ax = plt.subplots(1, 1, figsize=(6, 6))
ax.plot(df.x, df.y, linestyle='-', marker='o')
ax.set_xlabel('x')
ax.set_ylabel('y')
plt.show()
巡回セールスマン問題を解くために Ortoolpy の tsp を利用します.まず,tsp の利用方法を help で確認してみます.
help(tsp)
Help on function tsp in module ortoolpy.etc:
tsp(nodes, dist=None, method=None)
巡回セールスマン問題
入力
nodes: 点(dist未指定時は、座標)のリスト
dist: (i, j)をキー、距離を値とした辞書
method: 計算方法(ex. 'ortools')
出力
距離と点番号リスト
tsp を用いると簡単に巡回セールスマン問題を解くことができます.移動の総コスト(距離・時間)とその巡回経路が得られました.
巡回セールスマン問題を解く
results = tsp(df)
print(results)
(23793.968769870407, [0, 1, 3, 5, 7, 2, 8, 4, 6])
巡回経路だけを取得します.
巡回経路だけを取得
route = results[1]
print(route)
[0, 1, 3, 5, 7, 2, 8, 4, 6]
ノードの x 座標を巡回経路順に取得するには次のようにします.
print(df.x[route])
0 2000 1 5000 3 8000 5 7000 7 5000 2 6000 8 4000 4 1000 6 3000 Name: x, dtype: int64
この方法を使うと,折れ線グラフとして巡回経路を描くことができます.
fig, ax = plt.subplots(1, 1, figsize=(6, 6))
ax.plot(df.x[route], df.y[route], linestyle='-', marker='o')
ax.set_xlabel('x')
ax.set_ylabel('y')
plt.show()
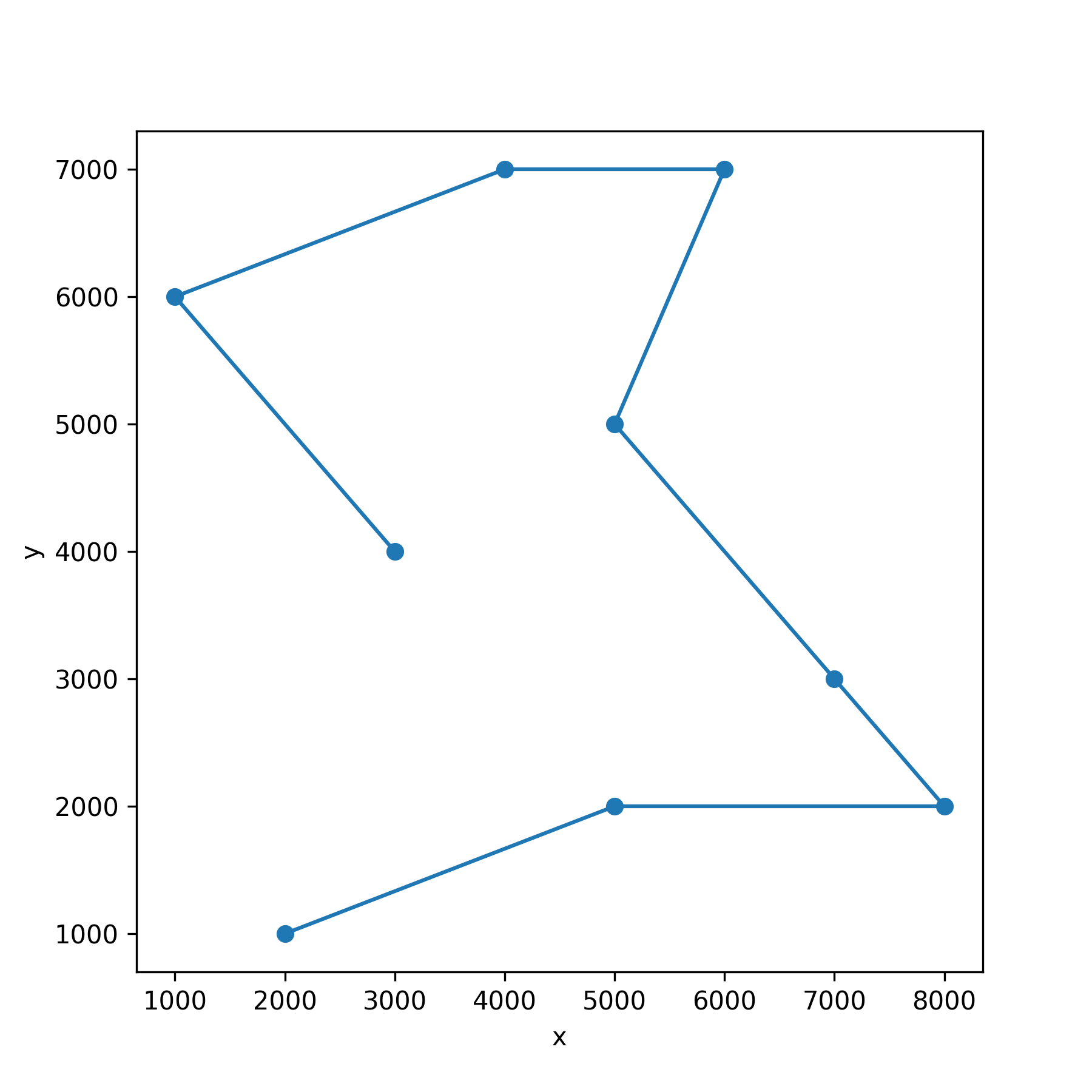
ただし,地点 0 を出発して地点 6 で終了していることが気になります.巡回経路の出発点を経路の最後にも追加します.これによって出発地点 0 に戻るようになります.
route.append(route[0])
print(route)
[0, 1, 3, 5, 7, 2, 8, 4, 6, 0]
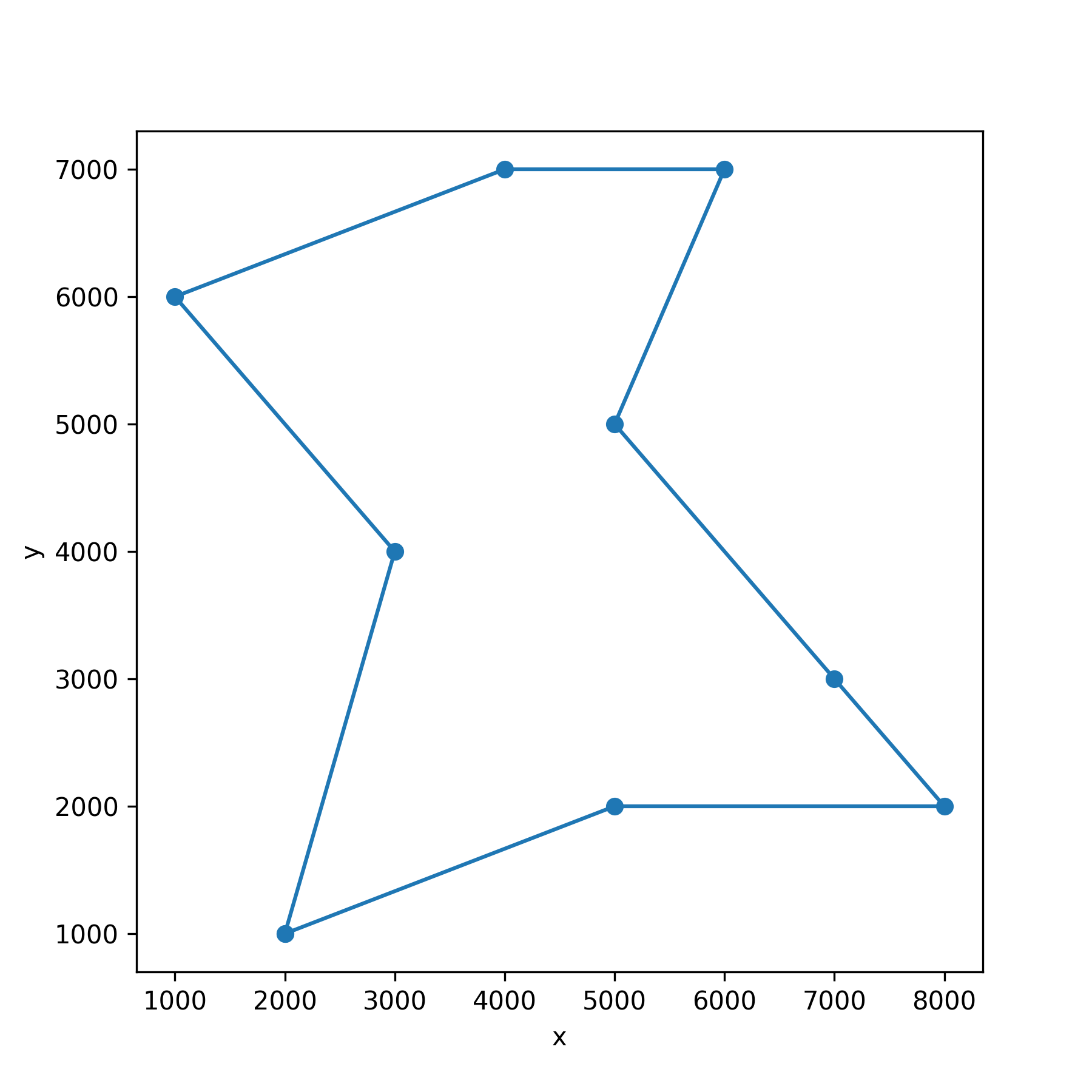
もう一度グラフを描きます.これで出発地点に戻ることができました.
fig, ax = plt.subplots(1, 1, figsize=(6, 6))
ax.plot(df.x[route], df.y[route], linestyle='-', marker='o')
ax.set_xlabel('x')
ax.set_ylabel('y')
plt.show()
距離データも利用して巡回セールスマン問題を解く
これまではノード間(座標間)の直線距離を利用して計算していました.次にノード間の距離データも利用した巡回セールスマン問題を解くことを考えます.
簡単化のために,ここでもノード間の直線距離をデータとして準備してみましょう.例えばノード0(2000, 1000)とノード1(5000, 2000)の直線距離は三平方の定理(ピタゴラスの定理)を用いて次のとおり計算できるはずです.
三平方の定理を用いてノード間距離を求める
print(nodes[0])
print(nodes[1])
print((3000**2 + 1000**2)**(1/2))
[2000, 1000]
[5000, 2000]
3162.2776601683795
すべてのノード間の距離を一気に求めるために次の方法を利用します.なお,採用する計算手法によっては tsp に与える距離データが整数 (integer) でなければならないため,astype(int) によって整数化をしておきます.上と同じ(ただし整数化された)結果が得られていることに注意してください.
距離行列を求める
dist = distance.cdist(df.values, df.values).astype(int)
print(dist)
[[ 0 3162 7211 6082 5099 5385 3162 5000 6324] [3162 0 5099 3000 5656 2236 2828 3000 5099] [7211 5099 0 5385 5099 4123 4242 2236 2000] [6082 3000 5385 0 8062 1414 5385 4242 6403] [5099 5656 5099 8062 0 6708 2828 4123 3162] [5385 2236 4123 1414 6708 0 4123 2828 5000] [3162 2828 4242 5385 2828 4123 0 2236 3162] [5000 3000 2236 4242 4123 2828 2236 0 2236] [6324 5099 2000 6403 3162 5000 3162 2236 0]]
距離行列も利用して巡回経路を求めるには次のようにします.なお,この場合は厳密解法が利用されます.距離行列は地点間の直線距離(ユークリッド距離)(ただし,距離は整数化された値)を求めていることから,距離行列を用いない方法とほぼ同じ結果(同じ巡回経路で,最小距離がわずかに異なる結果)になっていることに注意してください.なお,次のコードの場合は整数化しない距離行列であっても計算可能です.
距離行列を指定して巡回経路を求める
results = tsp(df, dist)
print(results)
(23792.0, [0, 1, 3, 5, 7, 2, 8, 4, 6])
解法を指定することもでき,次のとおり,ortools を指定した場合は近似解法になります.ただし,この場合は距離行列は整数化が必須です.今回の例題は問題の規模が小さいため同じ結果が得られました.規模の大きな問題を解く場合など必要に応じて解法を選択してください.なお,ortools は別途インストールが必要になるはずです.
解法を指定
results = tsp(df, dist, method='ortools')
print(results)
(np.int64(23792), [0, 1, 3, 5, 7, 2, 8, 4, 6])
上で求めた最適な巡回経路において,地点1の次に訪問する地点は3でした.この間の距離は3000です.
距離行列を表示
print(dist)
[[ 0 3162 7211 6082 5099 5385 3162 5000 6324]
[3162 0 5099 3000 5656 2236 2828 3000 5099]
[7211 5099 0 5385 5099 4123 4242 2236 2000]
[6082 3000 5385 0 8062 1414 5385 4242 6403]
[5099 5656 5099 8062 0 6708 2828 4123 3162]
[5385 2236 4123 1414 6708 0 4123 2828 5000]
[3162 2828 4242 5385 2828 4123 0 2236 3162]
[5000 3000 2236 4242 4123 2828 2236 0 2236]
[6324 5099 2000 6403 3162 5000 3162 2236 0]]
地点1から3の距離を9999に書き換えます.なお,逆向きに地点3から地点1への距離は3000のままであることに注意してください.この場合の最適な巡回経路はどのようになるでしょうか?直感的にはこの地点1から3への移動は避けることになりそうです.
地点1から3への距離を修正
dist[1][3] = 9999
print(dist)
[[ 0 3162 7211 6082 5099 5385 3162 5000 6324] [3162 0 5099 9999 5656 2236 2828 3000 5099] [7211 5099 0 5385 5099 4123 4242 2236 2000] [6082 3000 5385 0 8062 1414 5385 4242 6403] [5099 5656 5099 8062 0 6708 2828 4123 3162] [5385 2236 4123 1414 6708 0 4123 2828 5000] [3162 2828 4242 5385 2828 4123 0 2236 3162] [5000 3000 2236 4242 4123 2828 2236 0 2236] [6324 5099 2000 6403 3162 5000 3162 2236 0]]
距離行列を利用しない場合は次の巡回経路が最短でした.
距離行列を利用しない巡回経路
results = tsp(df)
print(results)
(23793.968769870407, [0, 1, 3, 5, 7, 2, 8, 4, 6])
地点1から3への距離を変更した場合の結果は次のようになりました.つまり,完全に逆向きの巡回経路が得られたことに注意してください.
修正した距離行列を利用した巡回経路
results = tsp(df, dist)
print(results)
(23792.0, [0, 6, 4, 8, 2, 7, 5, 3, 1])